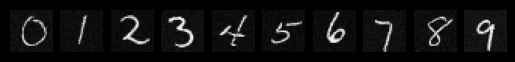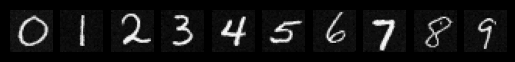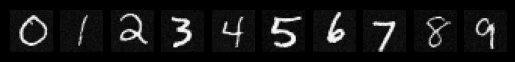Denoising Diffusion Models
Table of Contents
Part A: Pre-trained Diffusion Models
Abstract
Denoising diffusion models learn the underlying probability distribution of a dataset of natural images and sample from it to create new images not in the original dataset. In this project we use the diffusion model DeepFloyd IF to generate new images, similar images, image edits, visual anagrams and hybrid images. We then create our own denoising model and diffusion model to denoise and generate MNIST digit images.
Part A: Pre-trained Diffusion Models
In this part we use DeepFloyd IF, an open source model on Hugging Face for a variety of image generation tasks. DeepFloyd IF is a novel state-of-the-art open-source text-to-image model with a high degree of photorealism and language understanding. The model is a modular composed of a frozen text encoder and three cascaded pixel diffusion modules. For most of this part we will only use the first two cascaded pixel diffusion modules due to memory constraints.
Image Generation
We can start by passing in several prompts to the model to do conditioned generation. The model has been conditioned using text embeddings which allows the model to generate images of specific object descriptions. Diffusion models create new images by starting with entirely noisy images and iteratively removing noise for a certain number of inference steps which we can specify. For this project we seed all random generation with the value 2718 to ensure reproducibility.
Phase 1: 20 steps, Phase 2: 20 steps



Phase 1: 10 steps, Phase 2: 10 steps



Sampling Loops
Below we implement the forward process of diffusion models which progressively adds Gaussian noise to clean images. The process involves scaling the original image and adding noise according to a predefined schedule. We demonstrate this by adding increasing amounts of noise to test images at different timesteps, showing the gradual degradation of image quality.




Classical Denoising
We explore traditional denoising methods using Gaussian blur filtering on images with varying levels of noise. This classical approach demonstrates the limitations of conventional denoising techniques when dealing with significant noise, particularly at higher timesteps in the diffusion process.



One-Step Denoising
Using a pretrained UNet model, we implement single-step denoising by estimating and removing Gaussian noise from corrupted images. The model is conditioned on both the noise level and a text prompt, demonstrating improved denoising capabilities compared to classical methods, though with diminishing effectiveness at higher noise levels. (Note that the original image has been resized to 64x64 and the denoised images have been upsampled using a super-resolution model).



Iterative Denoising
We implement an iterative denoising process that gradually removes noise through multiple steps, using a strided approach to balance computational efficiency with denoising quality. This method demonstrates significantly improved results compared to single-step denoising, particularly for images with high noise levels.







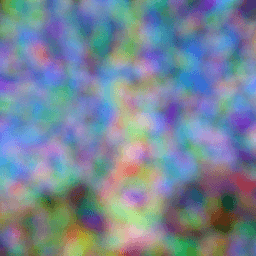
Diffusion Model Sampling
We explore image generation by applying the iterative denoising process to pure random noise. This demonstrates the model's ability to generate novel images from scratch, though the initial results show limitations in image quality and coherence without additional guidance.





Classifier-Free Guidance
We implement Classifier-Free Guidance (CFG) to enhance image generation quality. This technique combines conditional and unconditional noise estimates with a scaling factor, resulting in significantly improved image quality at the cost of reduced diversity in the generated samples.





Image-to-image Translation
We explore image editing through controlled noise addition and denoising, following the SDEdit algorithm. This process allows for varying degrees of image manipulation by adjusting the noise level, demonstrating how the diffusion model can modify existing images while maintaining certain original characteristics.















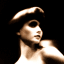


Editing Hand-Drawn and Web Images
We explore the model's ability to project non-realistic images onto the natural image manifold. This process works particularly well with paintings, sketches, and scribbles. We experiment with both web-sourced images and hand-drawn inputs, applying varying levels of noise to observe the transformation process.
Web-Sourced Image







Hand-Drawn Images













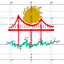
Inpainting
We implement image inpainting using diffusion models, allowing for selective image editing through masked regions. The process involves maintaining original image content in unmasked areas while generating new content in masked regions through iterative denoising, following the RePaint methodology.






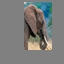




Text-Conditional Image-to-image Translation
We extend the image-to-image translation process by incorporating text prompts for guided image manipulation. This allows for more controlled transformations where the output images reflect both the original image structure and the semantic guidance provided by the text prompt.
Campanile > "a rocket ship"






Black Cat > "a photo of a hipster barista"






Silver Truck > "a photo of a dog"






Visual Anagrams
We create optical illusions using diffusion models by simultaneously denoising images with different text prompts in different orientations. The resulting images exhibit different appearances when viewed right-side up versus upside down, demonstrating the model's ability to encode multiple interpretations within a single image. The images below look like one scene when flipped one way, and a different scene when flipped the opposite way according to their conditional text prompt.






Hybrid Images
We implement Factorized Diffusion to create hybrid images that combine low-frequency components from one text prompt with high-frequency components from another. This technique produces images that appear different when viewed from varying distances, similar to classical hybrid image techniques but generated entirely through diffusion models.



Part B: Training a Diffusion Model
In this part, we implement and train our own diffusion model from scratch on the MNIST dataset. We start by building a simple UNet architecture for single-step denoising, then extend it to handle time conditioning for iterative denoising, and finally add class conditioning to enable controlled generation of specific digits.
Implementing UNets
We implement a UNet architecture consisting of downsampling and upsampling blocks with skip connections. The network includes standard operations like Conv2d, BatchNorm2d, GELU activation, and ConvTranspose2d layers. The architecture is designed with composed operations including ConvBlock, DownBlock, and UpBlock to create a deeper network while maintaining tensor dimensions. This forms the backbone of our denoising model with a hidden dimension of 128 channels.
Using the UNet to Train a Denoiser
We train the UNet as a single-step denoiser on MNIST digits using an L2 loss function. The model learns to map noisy images back to their clean counterparts. Training involves generating pairs of clean and noisy images using a fixed noise level σ, with the model optimized using Adam optimizer over 5 epochs. The training process shows progressive improvement in denoising capability, with significant enhancement in image quality between the first and final epochs.

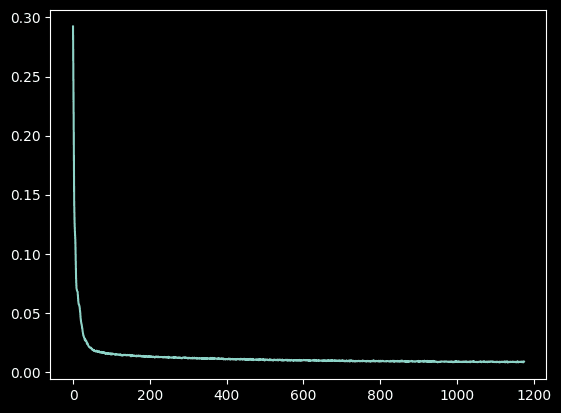
Out-of-Distribution Testing
We evaluate our trained denoiser's generalization capabilities by testing it on noise levels different from the training distribution. This experiment reveals the model's robustness and limitations when dealing with varying amounts of noise, demonstrating how well it can handle out-of-distribution scenarios in image denoising tasks.
Results after the 1st Epoch


Results after the 5th Epoch




Adding Time Conditioning to UNet
We extend our UNet architecture to incorporate time conditioning, enabling it to handle different noise levels during the diffusion process. This is implemented using FCBlocks (fully-connected blocks) that inject normalized timestep information into the network. The conditioning signal modulates the network's behavior at different stages of the denoising process, allowing for more precise control over noise removal.
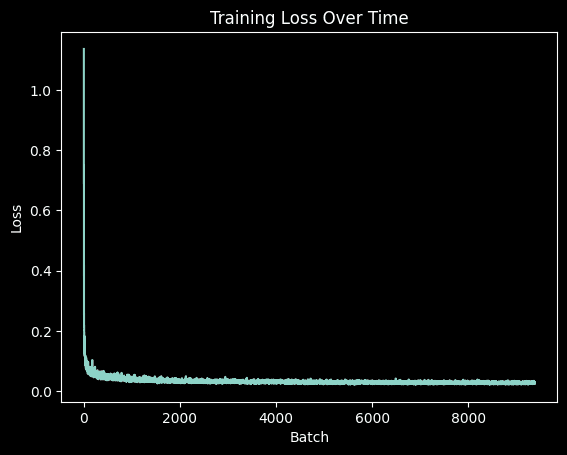
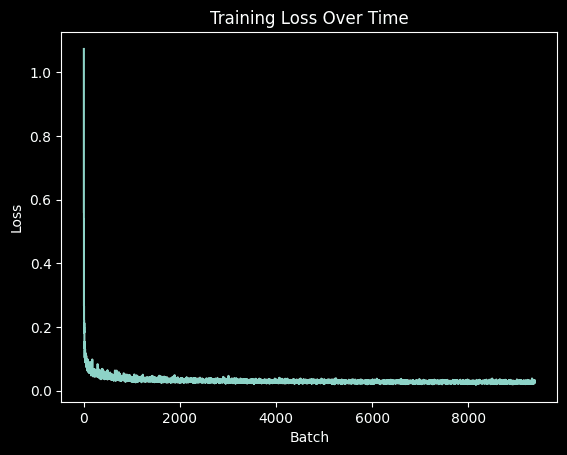
Training the Time-Conditioned UNet
The time-conditioned UNet is trained to predict noise in images given both the noisy input and a timestep. Training uses the MNIST dataset with a batch size of 128 over 20 epochs. We employ an Adam optimizer with an initial learning rate of 1e-3 and implement exponential learning rate decay. This more complex training task requires additional epochs compared to the simple denoiser to achieve optimal performance.
Sampling from the Time-Conditioned UNet
We implement a sampling process that starts from pure noise and iteratively applies the time-conditioned UNet to generate images. The process follows a predefined variance schedule with 300 timesteps, progressively denoising the image. The sampling algorithm demonstrates the model's ability to generate coherent digit images from random noise through iterative refinement.
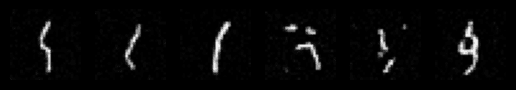

Adding Class Conditioning to UNet
We further enhance our UNet by adding class conditioning, allowing controlled generation of specific digits. The implementation uses additional FCBlocks with one-hot encoded class vectors and includes a dropout mechanism where class conditioning is randomly disabled 10% of the time during training. This enables the model to handle both conditional and unconditional generation scenarios.
Sampling from the Class-Conditioned UNet
The final sampling process incorporates classifier-free guidance with a guidance scale of 3 to improve the quality of conditional generation. This approach allows us to generate multiple instances of specific digits with high fidelity, demonstrating the model's ability to combine both time and class conditioning for controlled image generation.
Sampeled Digits after the 5th Epoch
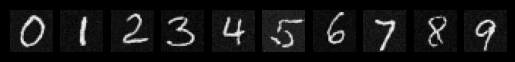
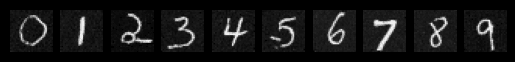
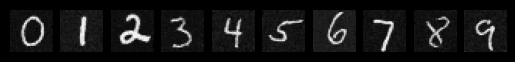
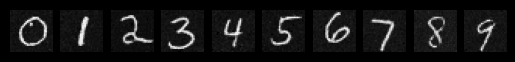
Sampeled Digits after the 20th Epoch